Michael Dunst

University of Pennsylvania Master of City Planning student
Passionate about and skilled in transportation planning, real estate development, and creating livable cities.
View My LinkedIn Profile
Estimating Home Values in Charlotte
Project description: The purpose of this project is to produce an algorithm (model) that can help the online real-estate website, Zillow.com, predict home sale prices with greater accuracy. Improving real-estate valuations are important for several reasons. Namely it:
- Improves user experience
- Provides context for anticipated property taxes and homeowner’s insurance
- Alleviates historic and systemic biases commonplace with home valuations in neighborhoods of color
1. Collecting Data
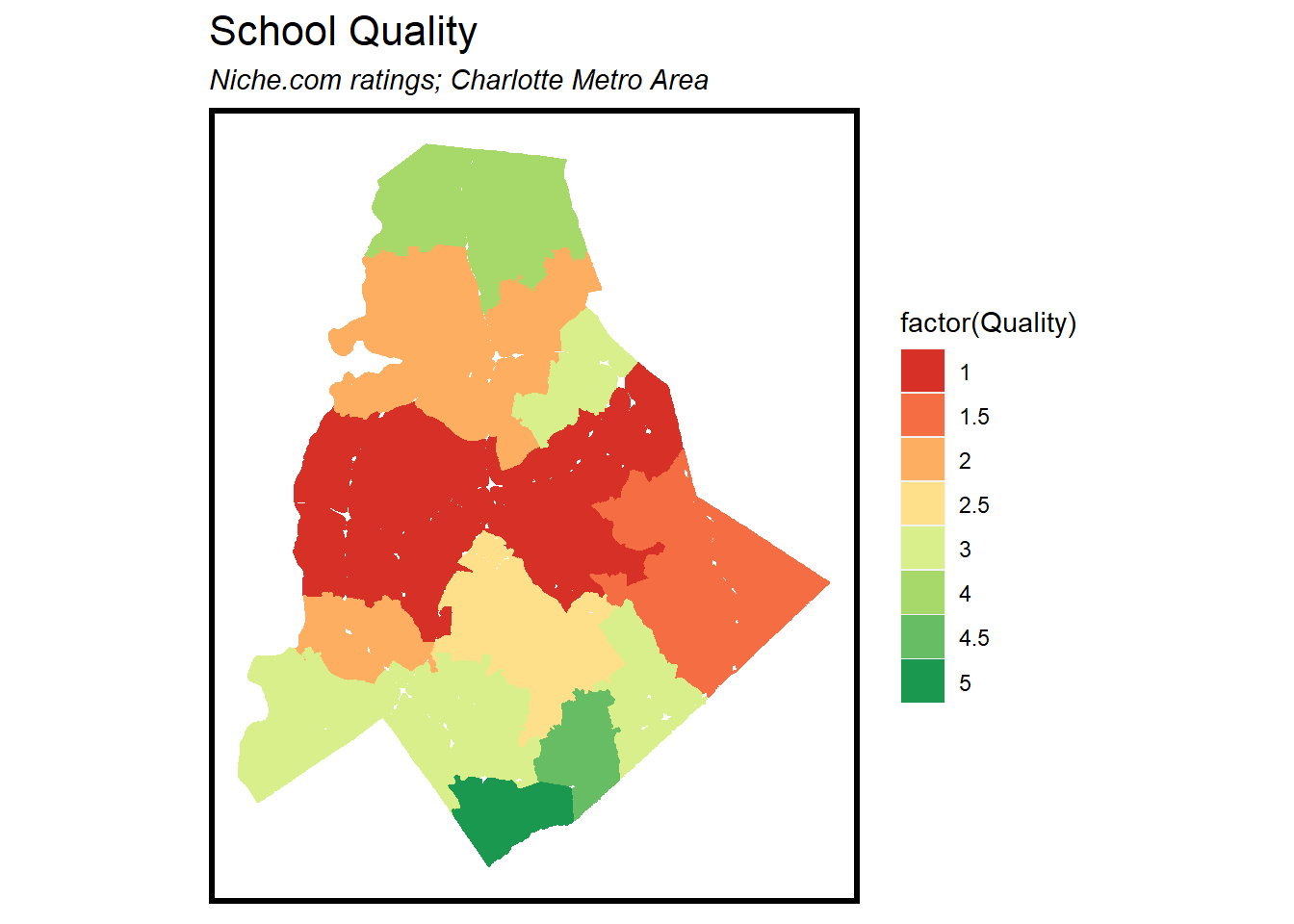
I brought in past scraped data from Zillow, amenity data such as school quality, park locations, and grocery locations. I also recoded existing variables to prepare them better for a regression model such as creating a price per square foot variable and converting a quality column into a categorical variable.
2. Predict for Test Data
I split the source data into training and test sets to calibrate the model. Then, I ran k-folds cross-validation on our data to improve accuracy.
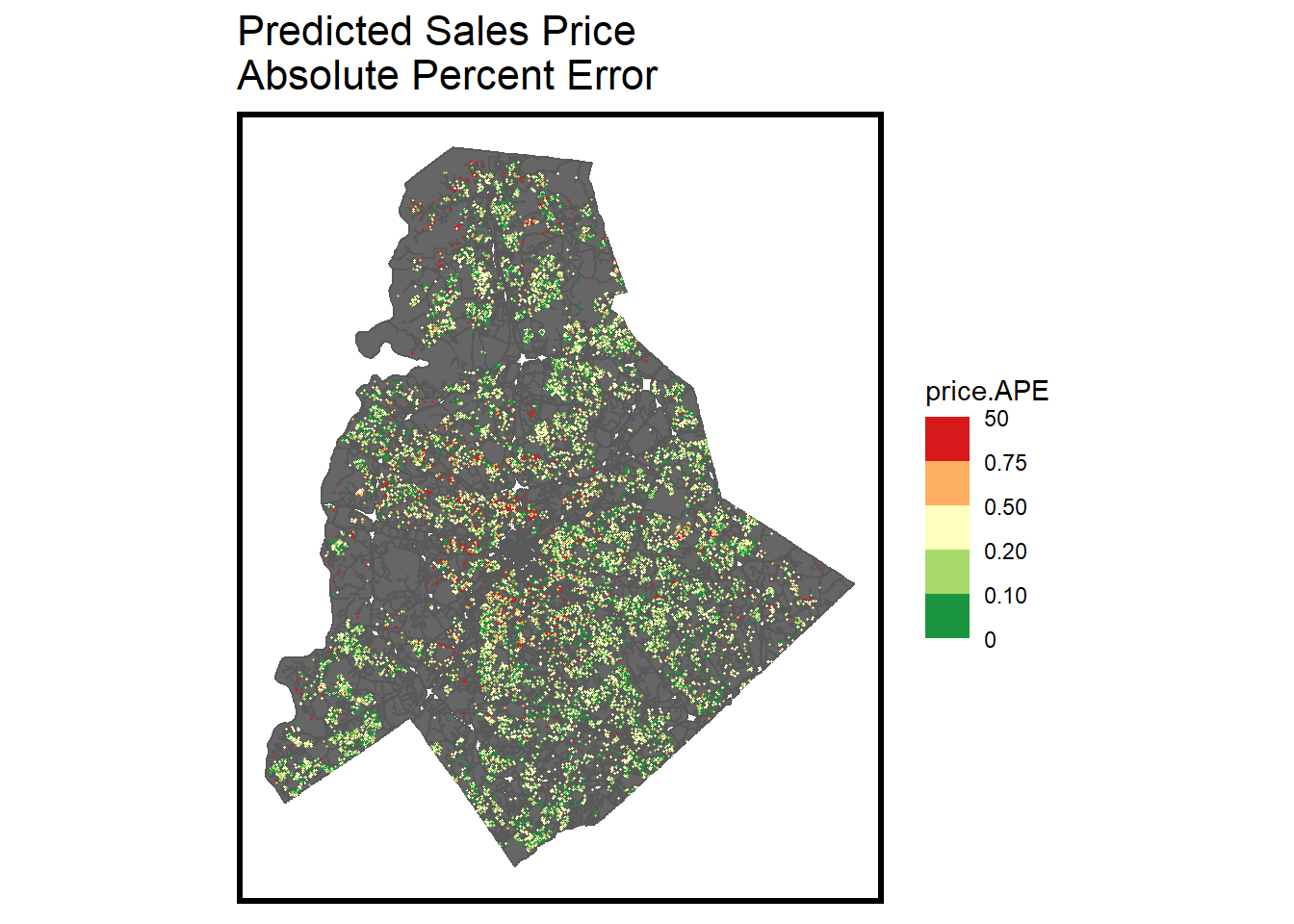
While error was generally low, the red dots indicate large errors and their clustering indicate a spatial correlation.
3. Evaluating Spatial Bias
By calculating Moran’s I for this dataset, we are determining if there is a spatial relationship among home sales in Charlotte. As seen in the outcome, Moran’s I was calculated to be high, meaning there is a spatial relationship in the predicted errors that must be accounted for.
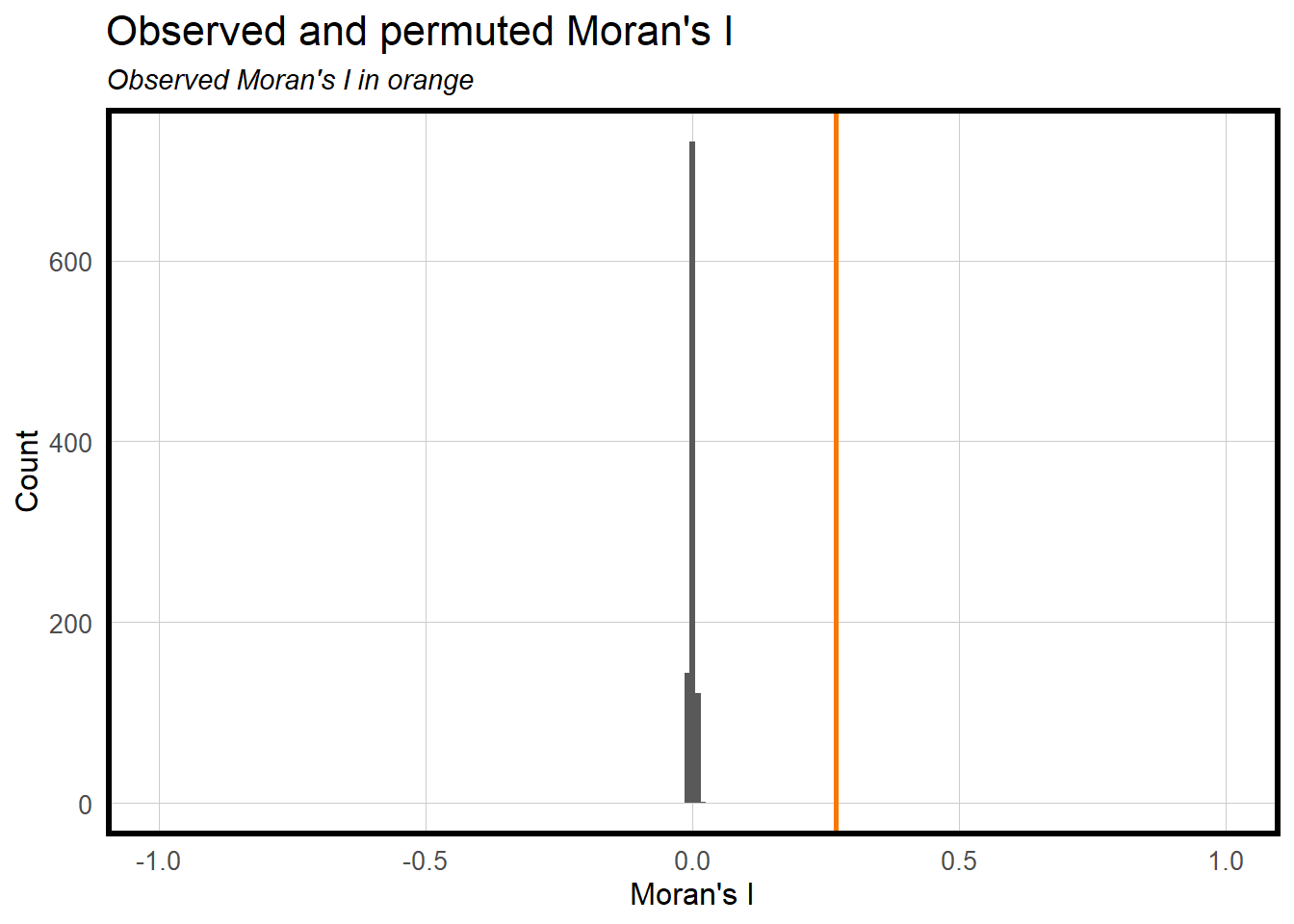
Therefore, we introduced the neighborhood of each property to control for spatial bias in our prediction.
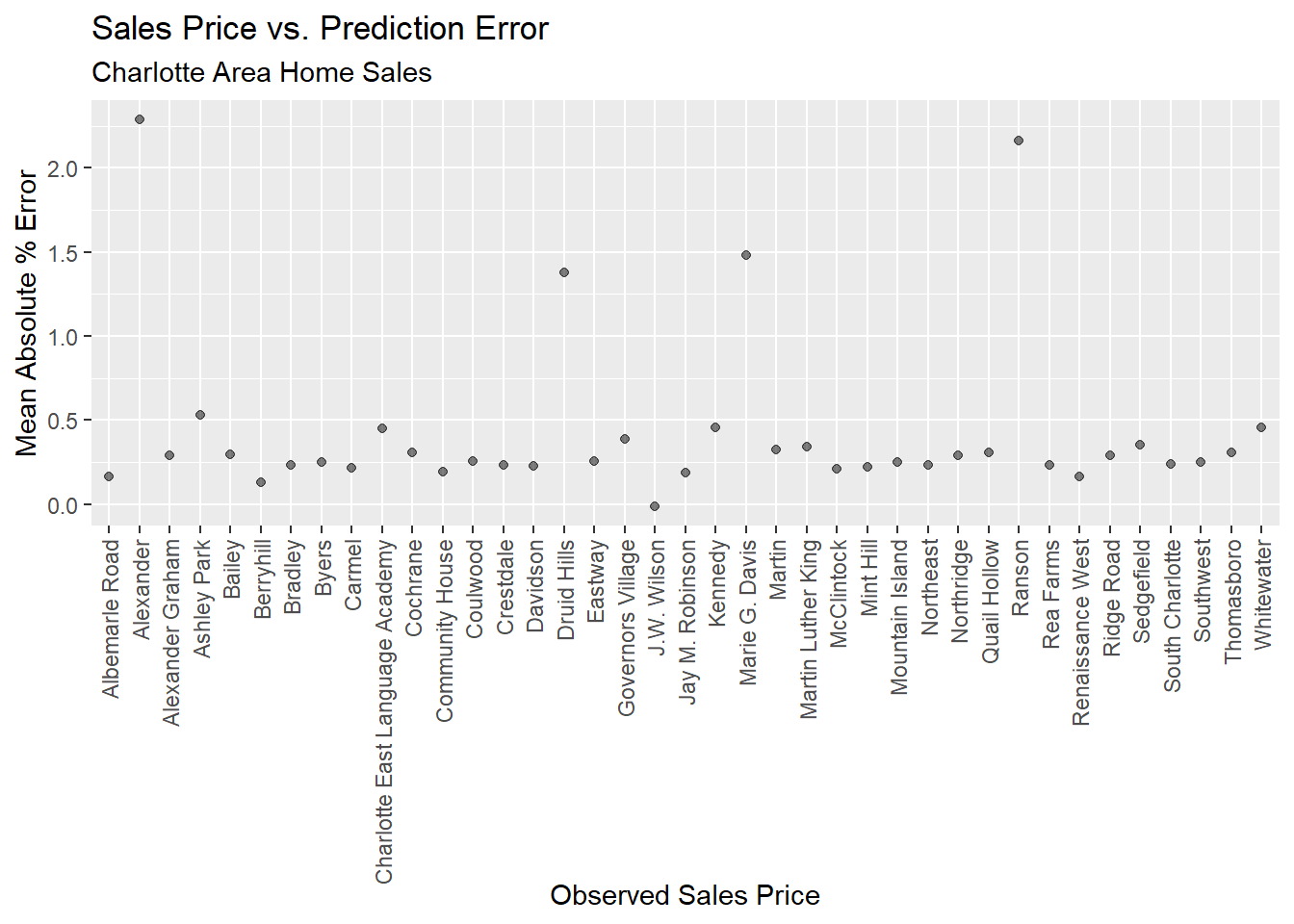
4. Conclusion
The variables are able to explain ~50% of the variation observed in Charlotte home prices (R squared). The mean absolute error (MAE) is 106593.9, indicating that on average, the model’s price predictions differ from actual home prices by ~$106,593. This is fair and may be due to outlier (costly homes) included in our dataset. Ultimately, the model is generalizeable, but requires some tweaks before a Zillow pitch meeting.
One way to improve the accuracy, in a way that wasn’t permitted, would be to take comparable properties into account. While we attempted to do so by proxy via variables like school quality and housing quality, directly modeling based on “comps” would be helpful.